关于写推荐系统时差点把公司的Redis搞崩这件事
目录
警告
本文最后更新于 2023-09-19,文中内容可能已过时。
最近在公司搬砖接到了这样一个需求:为推荐的商品增加推荐标签,类似这个样子:
其中有一个标签的需求是:用户有多少个朋友也购买了这款商品,很显然,这个数据很适合用 Redis Hash 存储:
- key:用户Id
- field:商品Id
- value:朋友中也购买了这个商品的人数
看上去完美符合需求,通过用户Id和商品Id即可得知用户有多少朋友也购买了这个商品。设计好方案后,一通梭哈代码上线,问题出现了。
出现危机
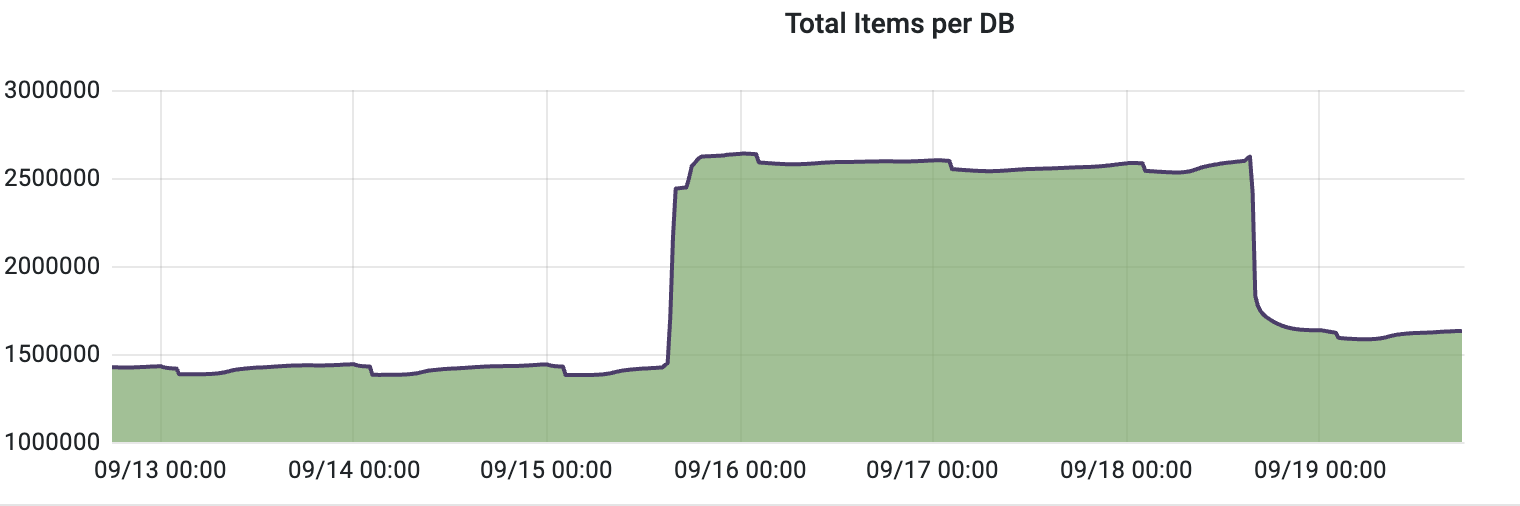
上线了代码后去看监控,代码执行了 10%,Redis 内存占用爆增 20%,可以预见我的代码还没跑完,Redis 内存就会被打满,我赶紧 KILL 掉程序去分析原因。
分析原因
问题的原因在于数据规模太大了,我们的用户数据量是千万级的,这意味着 Redis 中有上千万个 Key,每个用户大约有 100 个推荐商品,所以总共需要在 Redis 中存储大约 10 亿个 Item,碰巧我用的那台 Redis 主机内存容量并不大,完全顶不住这个数据规模。
问题解决
解决方案有两个,要么节省内存占用,要么给 Redis 扩容。扩容绝对是下下策,所以我首先尝试能否节约内存。
通过数据分析我发现,很少有用户和他的朋友一起购买了被推荐的商品,也就是说大量的数据都是 0!那既然是 0,我完全可以不存储嘛。
修改代码,上线,最终 Redis 内存只上升了 1%!
脏数据清理
现在是时候清理战场了,这里我用了一个小技巧极大的降低了脏数据的清理工作:更换 Key 的名称。这样的话脏数据在 Key 过期时会被 Redis 清理掉,就不需要我写代码手动清理了。
经验总结
经验➕1:在存储数据前预判总体数据规模,我把这条记录在了我的这篇博文里:Redis玩家积累的血泪经验
最后给大家看看当时的数据监控😂
Buy me a coffee~
 支付宝
支付宝
 微信
微信