场景一:过滤因子
“获取置顶评论列表” 出现慢SQL:
1
2
3
4
|
SELECT * FROM mi_group_topic_comment
WHERE topic_id IN (23965590, 23973239, 23989372, 24006394, 24056713, 24126219, 24234899, 24282453, 24328024, 24359605, 24394164, 24446125, 24459075, 24459157, 24459221, 24496994, 24652752, 24709572, 24723144, 24723523, 24724124, 24778731, 24792317, 24801288, 24828960, 24880167, 24891600, 24891642, 24891678, 28617343)
AND status = 1
AND is_sticky = 1
|
mi_group_topic_comment表的情况如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
show create table mi_group_topic_comment \G
***************************[ 1. row ]***************************
Table | mi_group_topic_comment
Create Table | CREATE TABLE `mi_group_topic_comment` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`group_id` bigint(20) NOT NULL DEFAULT '0',
`topic_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL DEFAULT '0',
`repliee_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '被回复者id',
`parent_id` bigint(20) DEFAULT '0' COMMENT '根评论id',
`content` varchar(15000) DEFAULT '',
`timestamp` bigint(13) DEFAULT '0',
`status` tinyint(1) DEFAULT '1' COMMENT '状态(0:已删除,1:正常,2:审核中,-4~-9:创宇审核结果,-10~-17:腾讯审核结果,-20:内部审核不通过)',
`is_sticky` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否置顶(0:非置顶,1:置顶)',
`stick_time` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '置顶时间',
PRIMARY KEY (`id`),
KEY `parent_id` (`parent_id`),
KEY `idx_group_id` (`group_id`),
KEY `i_TopicID_Status_Timestamp` (`topic_id`,`status`,`timestamp`),
KEY `i_TopicID_Status_ParentID_Timestamp` (`topic_id`,`status`,`parent_id`,`timestamp`),
KEY `i_UserID_Status_Timestamp` (`user_id`,`status`,`timestamp`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=48909707 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC
|
分析各个字段的过滤因子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
select count(*) from mi_group_topic_comment where 1
+----------+
| count(*) |
+----------+
| 48913431 |
+----------+
select count(*) from mi_group_topic_comment where is_sticky = 1
+----------+
| count(*) |
+----------+
| 180 |
+----------+
select count(*) from mi_group_topic_comment where status = 1
+----------+
| count(*) |
+----------+
| 45471872 |
+----------+
|
根据数据可以得出:is_sticky 适合建立索引,并且放置在首位。
- sql中的WHERE条件是
WHERE is_sticky=1表中is_sticky=1的数据量非常小,检索效率非常的高。
- 未来预计不会出现
WHERE is_sticky=0这种sql(专门查询未被置顶的评论)。即使出现了WHERE is_sticky=0 这种sql,预计Mysql优化器会选择表中的索引i_TopicID_Status_Timestamp,大概率也不会产生慢查询。
总结:
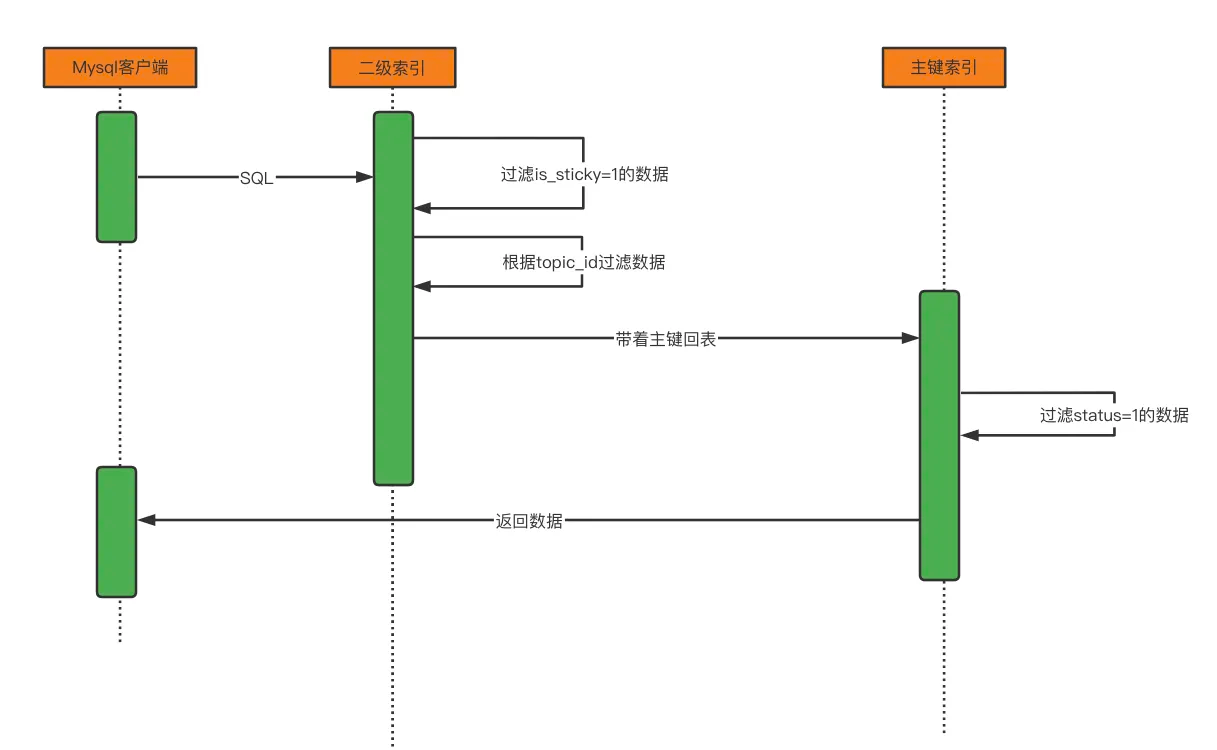
建立索引i_IsSticky_TopicId(is_sticky, topic_id) 是一个可行的方案。
预计MySQL会产生如下行为:
场景二:Using filesort
业务报警出现慢SQL:
1
2
3
4
5
6
7
8
9
10
|
SELECT *
FROM mi_group_topic
WHERE group_id = 364559
AND (is_all_visible = 0 AND questionee_id = 5168100)
AND is_ignored = 0
AND status = 1
AND timestamp >= 0
AND timestamp <= 1671515923000
ORDER BY timestamp DESC
LIMIT 30
|
使用 Explain 查看执行计划:
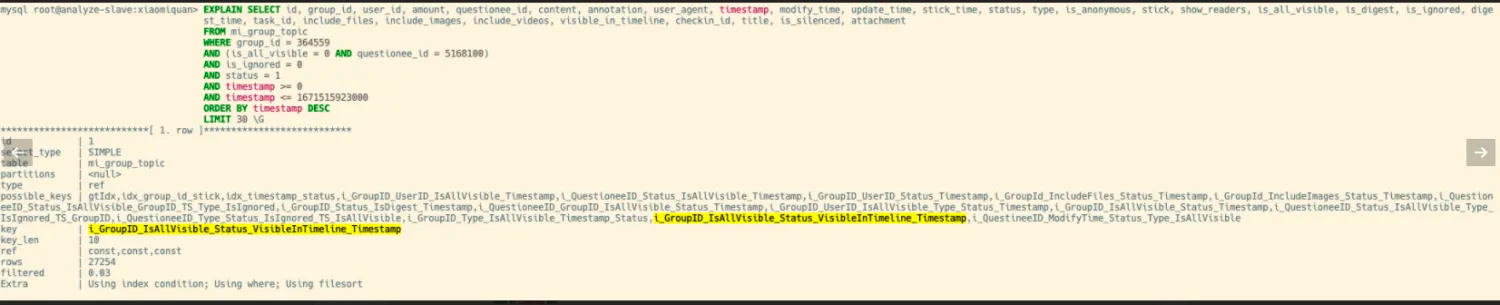
- 执行时间:2.153s
- 命中索引:KEY
i_GroupID_IsAllVisible_Status_VisibleInTimeline_Timestamp(group_id,is_all_visible,status,visible_in_timeline,timestamp)
- Extra:Using filesort,有文件排序。
”解决方案:“
该表已经有25个索引,不建议新增索引了,从现有的索引中选择出一个索引解决问题:
KEY i_QuestioneeID_GroupID_IsAllVisible_Status_Timestamp(questionee_id,group_id,is_all_visible,status,timestamp)
上述索引的前三个字段保证了比较小的过滤因子,索引末尾的timestamp字段保证了利用索引排序,而非文件排序。
”测试新索引性能:“
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
EXPLAIN SELECT id, group_id, user_id, amount, questionee_id, content, annotation, user_agent, timestamp, modify_time, update_time, stick_time, status, type, is_anonymous, stick, show_readers, is_all_visible, is_digest, is_ignored, digest_time, task_id, include_files, include_images, include_videos, visible_in_timeline, checkin_id, title, is_silenced, attachment
FROM mi_group_topic
FORCE INDEX (i_QuestioneeID_GroupID_IsAllVisible_Status_Timestamp)
WHERE group_id = 840536
AND (is_all_visible = 0 AND questionee_id = 5574577)
AND is_ignored = 0
AND status = 1
AND timestamp >= 0
AND timestamp <= 1671515923000
ORDER BY timestamp DESC
LIMIT 30
---------------------------------------------------------------------
Time: 0.017s
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | mi_group_topic
partitions | <null>
type | range
possible_keys | i_QuestioneeID_GroupID_IsAllVisible_Status_Timestamp
key | i_QuestioneeID_GroupID_IsAllVisible_Status_Timestamp
key_len | 26
ref | <null>
rows | 9330
filtered | 10.0
Extra | Using index condition; Using where
|
可见 Extra 字段已经没有 Using filesort,执行时间达到 0.017s,快了 100 多倍。
场景三:MySQL未选择最优索引
MySQL优化器做的不那么好,面对复杂SQL的时候可能不会选择最优索引,这时需要FORCE INDEX,具体可以看“场景二”。
原文链接:实战:SQL优化笔记
 支付宝
支付宝
 微信
微信